所属领域: A 电子信息技术
技术成果简介
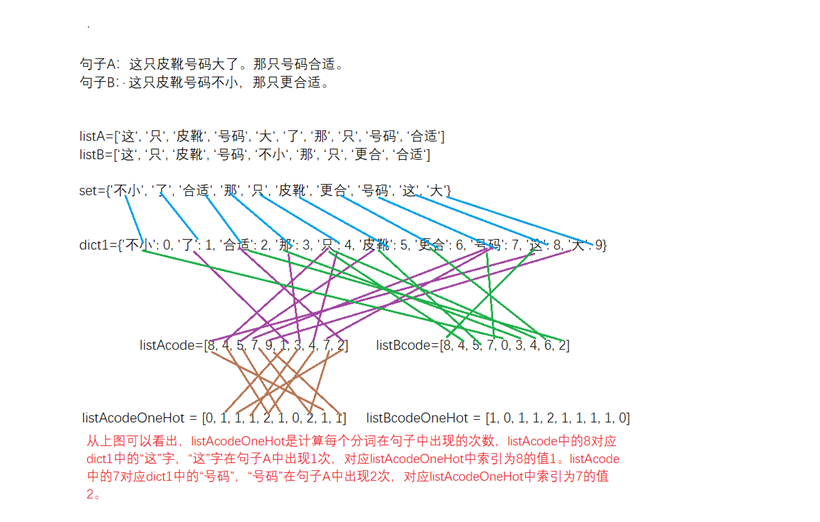
随着信息技术、网络技术的快速发展,网络信息也同样得以飞速增长,同时也带来了数据量的海量增长。在当下,网络数据已经日益渗透于人们日常生活的方方面面,只要有知识数据或者信息处理的地方就有可能用到文本相似度匹配算法。对于语义的推测以及分析也可以建立于文本相似度的基础上。现有的计算文本相似度的方法有模糊匹配这类计算两个文本之间的编辑距离的方法;也有如欧氏距离、余弦距离等组成向量算法,通过计算两个向量组之间距离以此来判读两个向量的相似度进而判断文本的相似度;还有杰卡德相似度系数,即通过计算两个文本的交集和并集之比计算相似度系数。但是对于模糊匹配来说,如果用户输入文本与目标文本相差较大,那么对于文本进行增删改的操作会过多。对于余弦距离等组成向量的方法来说,对于词语分词处理的要求较高,在面对类似于数据库和用户输入均为不可再分词的情况下时,无法构成向量来计算相似度。对于应用杰卡德系数算法,其直接用于不可再分词语义推测时,若两个词不直接相同那么并集并不存在,亦为0,所以其推测结果同样不符合预期。针对现有技术中的上述不足,本发明公开了基于文本相似度和关键字的语义推测方法,对数据库中存储的文本进行分词处理,得到若干不可再分词,判断数据库中每个不可再分词的字符数,建立短语词典和词汇词典;对用户的输入文本进行分词处理,得到若干不可再分词,判断输入文本中每个不可再分词的字符数,得到短语列表和词汇列表中;将第二短语在所述短语词典中进行匹配,计算第一匹配度:若第一匹配度为1,输出匹配文本作为最终推测结果;若第一匹配度小于1,输出第一匹配度最高的一个或多个文本作为推测结果。本发明提供基于文本相似度和关键字的语义推测方法,以解决现有技术中运算量过大、推测结果不符合预期等问题,实现降低必要运算量、提高推测结果的准确性的目的。
技术成果前景
1、本发明基于文本相似度和关键字的语义推测方法,对于数据库和用户输入均进行分词处理,相较于现有的模糊匹配等编辑文本算法而言,可以有效减少运算量,避免了运算量的浪费。2、本发明基于文本相似度和关键字的语义推测方法,针对不可再分词提出了逐一字符匹配的相似度算法,得到各个字符对于各个词是否匹配,在语义推测过程中对两个词汇进行相似度计算的时候提供了现有的编辑距离算法之外的另一种新的计算方式。3、本发明基于文本相似度和关键字的语义推测方法,相较于现有的杰卡德相似度系数等算法而言,解决了其因并集不存在而导致的推测结果不符合预期的问题,并优化了在对字符进行操作时除数过大的问题,显著提高了推测结果的准确性。